Insights & Perspectives
Exploring the intersection of digital health, AI, and clinical innovation. Here are my latest thoughts and findings from the field.
December 5 - HealthTech Dose
December 5, 2025
This episode moves beyond conceptual discussions of Artificial Intelligence (AI) and focuses entirely on execution, delivering a clear, actionable roadmap for successfully implementing AI strategies. The mission is to shift the focus from small pilot projects toward full-scale operational integration across the entire drug development life cycle. To succeed this decade, executives must prioritize three immediate strategic mandates: Deep Operational Streamlining (accelerating trial execution and startup), Fit-for-Purpose Data Strategies (managing data volume through advanced biomarkers and regulatory alignment), and Pipeline Differentiation (leveraging quantum-informed AI and human-machine teaming). The key strategic win lies in embracing AI not as a replacement, but through Servant Leadership principles—delegating high-volume programmable tasks to AI while reserving complex judgment for human experts.
Key Takeaways:
Slash study startup times by treating research operations as a core business function; the Henry Ford Health initiative reduced startup time by 50% through restructuring and outsourcing.
Solve the accrual crisis (currently averaging 1.5 patients per cancer trial) by removing restrictive enrollment thresholds and utilizing multimodal AI to process unstructured patient data.
Combat the “Data Explosion” (projected to hit 6 million data points per trial by 2025) by shifting focus from volume to “fit-for-purpose” data, such as high-precision EEG biomarkers for Alzheimer’s.
Accelerate discovery 1000x by integrating hybrid quantum-AI simulations (e.g., Q-Simulate, Jero) to explore chemical spaces with unprecedented speed and accuracy.
Mitigate AI risk and hallucinations by implementing “Simultaneous Review” modes—where humans and AI review cases together—rather than sequential workflows, ensuring immediate validation and cognitive complementarity.
Show Notes:
[0:00 - 1:00] Introduction to the “Engine Room” of the industry: Why the status quo of 8.1-month trial startups and 170-day screening timelines is a public health failure.
[1:00 - 2:00] Operational Streamlining: A deep dive into the Henry Ford Health Initiative case study, which achieved a 50% decrease in study startup time and a massive increase in open protocols by restructuring financial and administrative support.
[2:00 - 3:00] Patient Centricity & Recruitment: How the Alzheimer’s “Overture” study accelerated recruitment by removing strict amyloid thresholds, and how Multimodal Large Language Models (LLMs) are breaking down data silos to match patients.
[3:00 - 4:00] AI Performance Metrics: The operational impact of AI pipelines—achieving 87-93% accuracy in cohort selection and reducing the time coordinators spend reviewing patient eligibility from nearly an hour to under 9 minutes.
[4:00 - 5:00] The Data Explosion: Discussing the jump from 930,000 data points (2012) to 6 million (2025), and the pivot toward “fit-for-purpose” data strategies like millisecond-precision EEG biomarkers over subjective clinical scales.
[5:00 - 6:00] Differentiation & Quantum AI: How companies are using quantum-informed AI to model molecular interactions 1000x faster than traditional methods, compressing discovery timelines from months to hours.
[6:00 - 7:00] Rare Disease & Risk Management: The “PopEve” model’s success in identifying rare disease variants (98% accuracy), balanced against the critical risks of AI data fabrication and tool misuse.
[7:00 - End] The Strategic Solution: Implementing “Servant Leadership” for AI—delegating programmable tasks to agents (96% faster/cheaper) while utilizing Simultaneous Human-AI Review to maximize safety and efficacy.
Podcast generated with the help of NotebookLM
Source Articles:
Quantum techniques offer a glimpse of next-generation medicine
Digital Biomarkers Are Reshaping Alzheimer’s Patient Experience And Data
How the Pharmaceutical Industry Can Work More Effectively with Hospitals to Grow Clinical Trials
Tony Hung: Reflections from ESMO AI and Digital Oncology 2025
How Do AI Agents Do Human Work? Comparing AI and Human Workflows Across Diverse Occupations

Stop Chasing Algorithms: Do This Instead
December 2, 2025
HT4LL-20251202
Hey there,
If you are trying to keep up with every new AI algorithm dropped on arXiv, you have already lost the race.
The speed of innovation in digital health is becoming suffocating for R&D leaders. One week the industry is buzzing about Large Language Models (LLMs) for patient engagement, and the next, the focus shifts to Digital Twins for n-of-1 trials. For executives like you, the pressure to adopt “the next big thing” creates a dangerous conflict with the reality of regulatory compliance and the need for rigorous evidence. You don’t need more tools; you need a structured way to validate the ones that actually move the needle.
Here is the reality check we need to navigate this noise:
Governance is an accelerator, not a bottleneck: Rigorous validation (VVUQ) is the only path to regulatory trust.
Control is better than convenience: Relying on closed-source models (like standard GPT) creates reproducibility risks you can’t afford.
External standards are failing: You cannot rely on journals to vet AI integrity; you must enforce internal standards immediately.
Let’s cut through the hype and look at the evidence.
If you’re feeling paralyzed by the sheer volume of AI options and want to move from “experimental” to “scalable,” then here are the resources you need to dig into to build a resilient strategy:
Weekly Resource List:
AI and Innovation in Clinical Trials (Read time: 15 mins)
Summary: This paper argues that the industry must shift focus from simply adopting powerful algorithms to mandating transparency and rigorous validation. It highlights how AI can optimize eligibility criteria using Real-World Data (RWD) and the use of Digital Twins for synthetic control arms.
Key Takeaway: Stop viewing validation as a compliance burden. Implementing Verification, Validation, and Uncertainty Quantification (VVUQ) is the only way to make your AI models distinct and trusted by regulators.
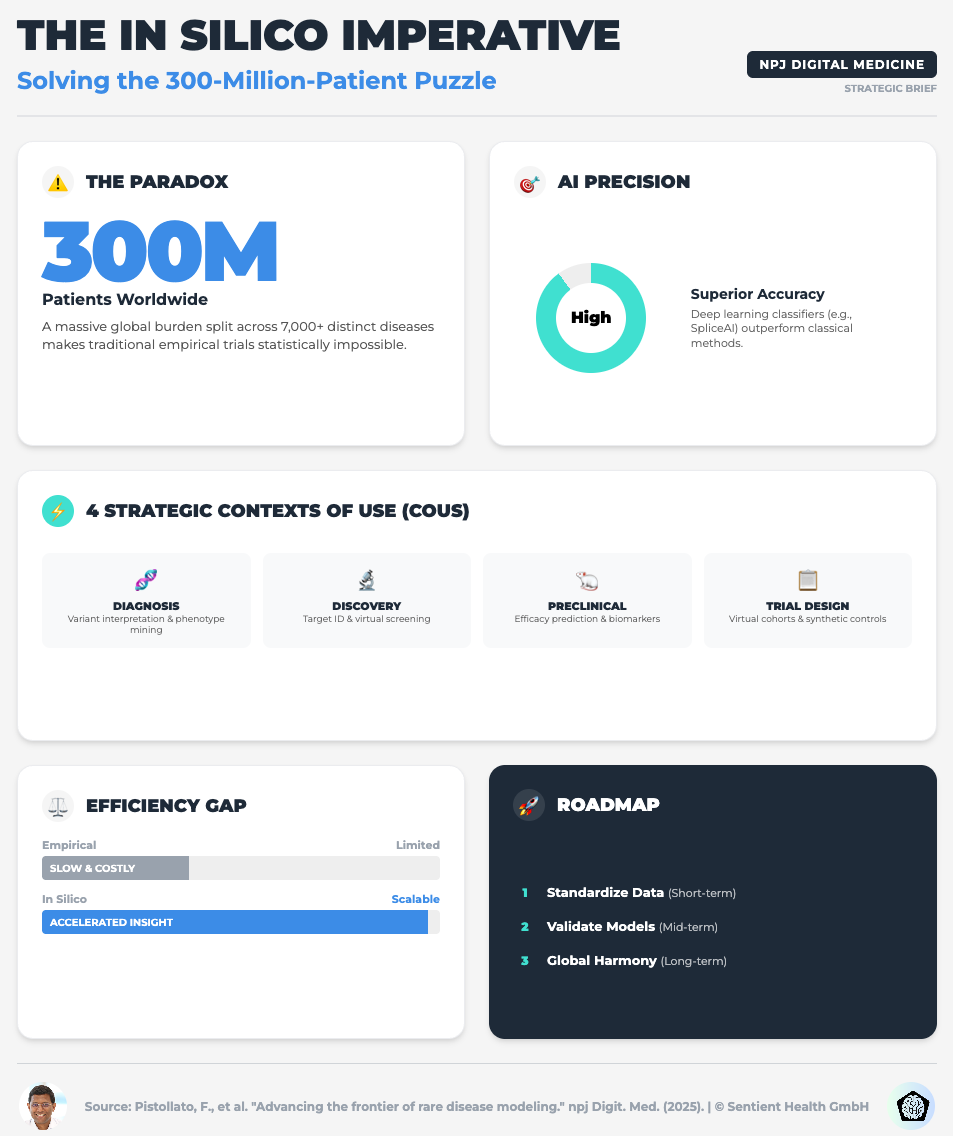
Advancing the Frontier of Rare Disease Modeling (Read time: 25 mins)
Summary: A deep dive into in-silico technologies, exploring how mechanistic models and machine learning are critical for small patient populations. It emphasizes the need for FAIR (Findable, Accessible, Interoperable, Reusable) data standards to make these models work.
Key Takeaway: For rare diseases, you cannot wait for more data. You must use Digital Twins and PBPK models to extrapolate dosing and simulate control arms, but this only works if your data infrastructure is interoperable.
AI in Diabetes Care: From Predictive Analytics to GenAI (Read time: 18 mins)
Summary: This piece explores the implementation challenges of GenAI in chronic disease management. It highlights the potential of GenAI to create privacy-preserving synthetic datasets and the risks of “data colonialism” (bias).
Key Takeaway: To avoid the risks of data privacy and bias, start using Federated Learning. This allows you to train models across diverse institutions without centralized data sharing, ensuring your AI is equitable and robust.

Evaluating AI Guidelines in Family Medicine Journals (Read time: 20 mins)
Summary: A shocking cross-sectional study revealing that only 5% of leading journals endorse AI-specific reporting guidelines like CONSORT-AI. The publishing landscape is failing to standardize AI governance.
Key Takeaway: Do not wait for publishers to set the bar. Mandate CONSORT-AI and SPIRIT-AI guidelines internally for all your R&D teams to safeguard your research credibility before it ever leaves the building.
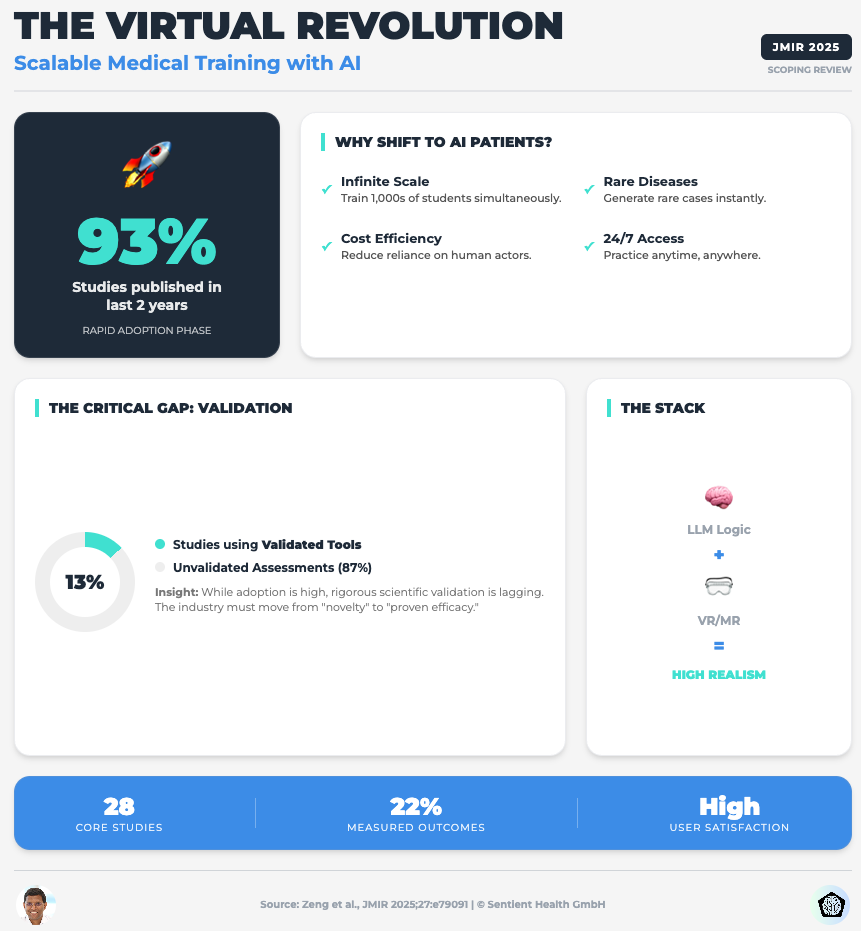
Embracing the Future of Medical Education With LLM-Based Virtual Patients (Read time: 22 mins)
Summary: A scoping review on using LLMs for simulation and training. It identifies a critical flaw: 87% of studies lack validated evaluation tools, and most rely on proprietary models (like GPT) that can change without notice, killing scientific reproducibility.
Key Takeaway: Move away from closed-source “black box” APIs for critical tools. To ensure data privacy and long-term reproducibility, you must prioritize open-source or local LLMs where you control the training data and parameters.
3 Steps To Tame AI Chaos With Strategic Governance Even If You Lack Technical Expertise
In order to achieve faster trials without exposing your organization to massive risk, you’re going to need a framework, not just a tech stack.
We often think “innovation” means buying the newest software. But in the current climate, innovation means having the discipline to validate what you build.
1. Optimize Eligibility Before You Recruit
The first thing you need to do is stop using AI just for data analysis and start using it for protocol design.
Why:
Traditional inclusion/exclusion criteria are often arbitrary and overly restrictive, leading to the enrollment crises we see today. The research shows that applying Machine Learning to Real-World Data (like EHRs) can identify where your criteria are too tight without impacting safety.
What to do:
Direct your data science teams to run simulations on your proposed eligibility criteria against RWD sets. Look for the “hidden” patients who are excluded by non-safety-critical factors. This can double your eligible pool before you open a single site.
2. Operationalize “VVUQ” Immediately
You need to integrate Verification, Validation, and Uncertainty Quantification (VVUQ) into your project management lifecycle.
Why:
“Black box” AI is a liability. If you cannot explain how a model reached a conclusion (Explainable AI or XAI), you cannot use it for clinical decision support. As the new data on virtual patients shows, reliance on unvalidated, proprietary models creates a reproducibility crisis.
What to do:
Don’t let a pilot project move to the next phase unless it has a “VVUQ Scorecard.” Ask your teams: Have we quantified the uncertainty? Is the model robust against edge cases? If OpenAI updates their model tomorrow, does our tool break? If the answer creates risk, the model stays in the lab.
3. Be Your Own Regulator
You need to mandate the use of CONSORT-AI and SPIRIT-AI reporting guidelines for every internal report and draft manuscript.
Why:
As the data showed, scientific journals are lagging behind. They aren’t catching hallucinations or methodological flaws in AI papers. If you rely on the peer-review process to validate your AI methods, you are exposing your firm to retraction risks later.
What to do:
Create a checklist based on these reporting guidelines. Make it a requirement for internal sign-off. By holding your internal teams to a higher standard than the journals do, you ensure that your data is bulletproof when it reaches the FDA or EMA.
PS...If you're enjoying Healthtech for Lifescience Leaders, please consider referring this edition to a friend.
And whenever you are ready, there are 2 ways I can help you:
AI Roadmap Kickstart Guide: Download my free guide on the 7 critical questions every pharma leader must answer before launching an AI initiative.
Strategy Session: Book a complimentary 30-minute AI Strategy Session with me to diagnose the biggest opportunities for AI within your current R&D pipeline.
November 28 - HealthTech Dose
November 28, 2025
This episode moves beyond conceptual discussions of Artificial Intelligence (AI) and focuses entirely on execution, delivering a clear, actionable roadmap for successfully implementing AI strategies in Pharma R&D. The mission is to shift the focus from general awareness toward specific strategic imperatives that manage the extreme complexity and scarcity defining modern drug development. To succeed this decade, executives must prioritize three immediate strategic mandates: Accelerating Trials (moving to “Context of Use 4” via digital twins and synthetic arms), Data Assurance (building trust through robust CDMS infrastructure and FAIR principles), and Product Differentiation (leveraging generative AI and diagnostics to stand out in the market).
The key strategic win lies in treating data infrastructure not as an IT cost center, but as a critical resilience asset that bridges the gap between computational models and experimental realities.
Key Takeaways:
Accelerate clinical execution by transitioning to “Context of Use 4” (actual clinical testing), utilizing digital twins to simulate dose responses in hard-to-recruit populations like those with congenital pseudoarthrosis of the tibia.
Reduce reliance on placebo arms by implementing synthetic control groups generated from historical data, a strategy increasingly accepted by regulators for rare diseases to address ethical and recruitment hurdles.
Optimize dosing precision by distinguishing between Physiologically Based Pharmacokinetic modeling (PBPK) for body-drug interactions and Quantitative Systems Pharmacology (QSP) for disease network efficacy.
Ensure regulatory assurance by investing in Cohort Data Management Systems (CDMS) that prioritize Non-Functional Requirements (NFRs) like scalability, security, and traceability over simple storage.
Combat data bias and silos by mandating FAIR principles (Findable, Accessible, Interoperable, Reusable) and harmonized standards (HPO, OMP) to make data machine-readable and transparent.
Achieve product differentiation by utilizing deep learning for non-invasive diagnostics (e.g., retinal scans for kidney disease) and deploying Large Language Model Virtual Patients (LLMVPs) to train prescribers in risk-free environments.
Show Notes:
[0:00 - 1:00] Introduction: R&D leaders must shift from feeling overwhelmed by AI speed to reframing it as the essential tool for managing complexity and scarcity in modern medicine.
[1:00 - 2:00] Priority 1: Accelerating Trials. The shift to “Context of Use 4” allows for the use of digital twins and simulation to predict efficacy in rare disease subgroups with tiny patient populations.
[2:00 - 3:00] The rise of Synthetic Control Arms: How using historical data to generate control groups is reducing the need for placebo arms, saving costs, and solving ethical dilemmas in pediatric rare diseases.
[3:00 - 4:00] Mechanistic Modeling: Understanding the critical difference between PBPK (drug movement in the body) and QSP (drug impact on disease networks) to optimize dosing for vulnerable groups like neonates.
[4:00 - 5:00] Priority 2: Assurance. Why high-quality input data is the bottleneck. The necessity of moving from basic databases to Cohort Data Management Systems (CDMS) built on “Non-Functional Requirements” (scalability/security).
[5:00 - 6:00] Building Regulatory Trust: Implementing FAIR principles and standardizing data (using HPO and OMP) to ensure transparency, interoperability, and the elimination of bias in genomic datasets.
[6:00 - 7:00] Priority 3: Differentiation. Using AI for superior diagnostics (e.g., deep learning on retinal images) and Generative AI to create synthetic data that preserves privacy while training robust models.
[7:00 - End] Future Workforce: The strategic value of “Large Language Model Virtual Patients” (LLMVPs) for training clinicians, and the final call to action: breaking down silos between computational and experimental teams.
Podcast generated with the help of NotebookLM
Source Articles:
Advancing the frontier of rare disease modeling: a critical appraisal of in silico technologies
Characteristics of cohort data management systems (CDMS): a scoping review
Full title: evaluating AI guidelines in leading family medicine journals: a cross-sectional study
Digital Lifestyle Interventions to Support Healthy Gestational Weight Gain: Scoping Review
Fabio Ynoe de Moraes: Clinical Trials Are Entering a New Era - And AI Is the Catalyst
From Concept to Code: Building High-Performance AI Platforms That Are Trusted
Tanja Obradovic: 4 Trends in Oncology Clinical Drug Development
Why most AI pilots fail to scale (and how to fix it)
November 25, 2025
HT4LL-20251125
Hey there,
We spend too much time obsessing over the accuracy of an algorithm and not enough time obsessing over whether a human will actually use it.
You have likely seen the “flash in the pan” scenario before: a digital health pilot that looks incredible on a quarterly review slide but crumbles the moment you try to roll it out to five different clinical sites. The issue usually isn’t the technology itself. It’s the friction—clinicians ignoring “black box” outputs, infrastructure that creates dual data entry, or tools that work in a pristine lab but fail in a clinic with spotty Wi-Fi. This disconnect slows down your trials, frustrates your site investigators, and keeps your organization stuck in “pilot purgatory.”
We are shifting gears today to look at scalability.
How to build trust so clinicians actually use the tools.
Why infrastructure (even offline modes) matters more than features.
How to move from siloed data to multimodal intelligence.
Let’s dive in.
If you are looking to move your organization from tentative experiments to robust, company-wide AI adoption, then here are the resources you need to dig into to build resilient systems:
Weekly Resource List:
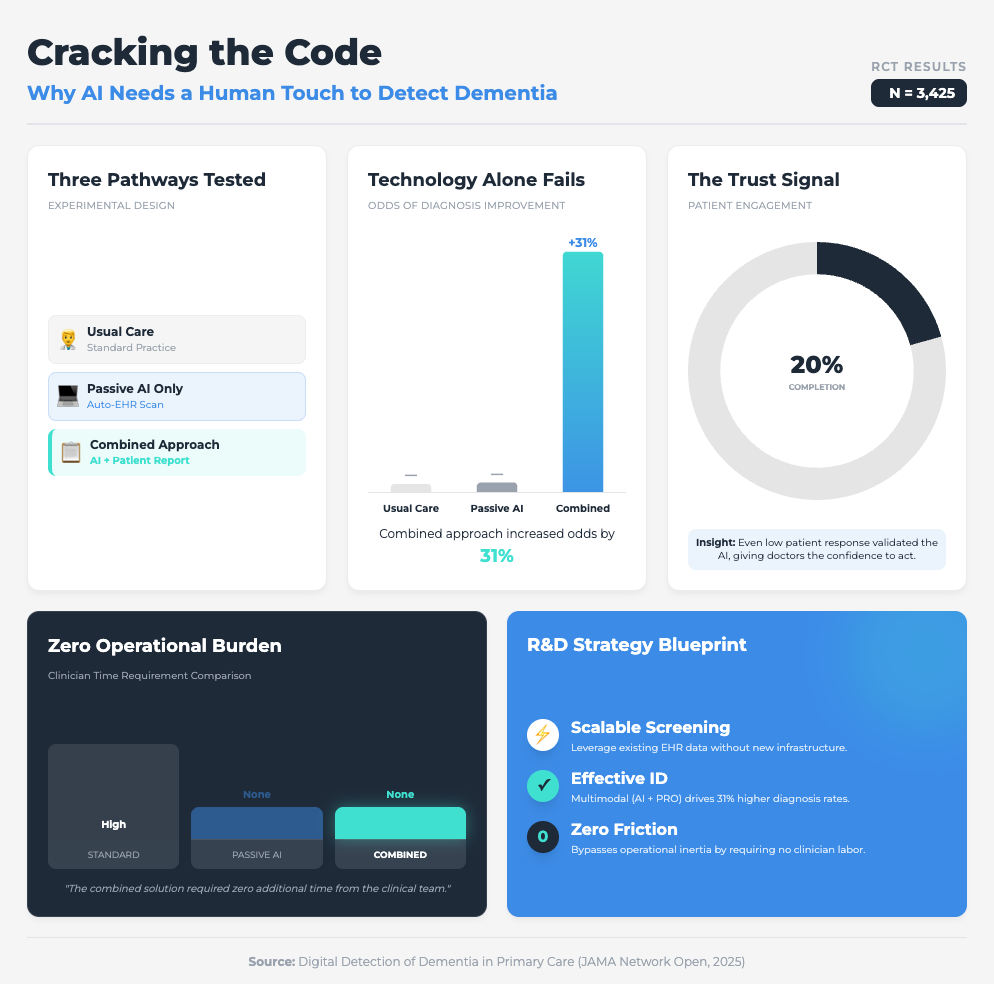
Digital Detection of Dementia in Primary Care (8 min read)
Summary: A randomized clinical trial compared a “usual care” approach against AI screening alone and AI combined with patient input. It highlighted that while passive digital markers alone were ignored by clinicians, adding a patient-reported outcome created a “check and balance” system that validated the data.
Key Takeaway: The “AI only” approach failed. The combined approach increased diagnoses by 31%. To scale AI, you must embed mechanisms (like patient-reported outcomes) that build clinician trust in the machine’s output.
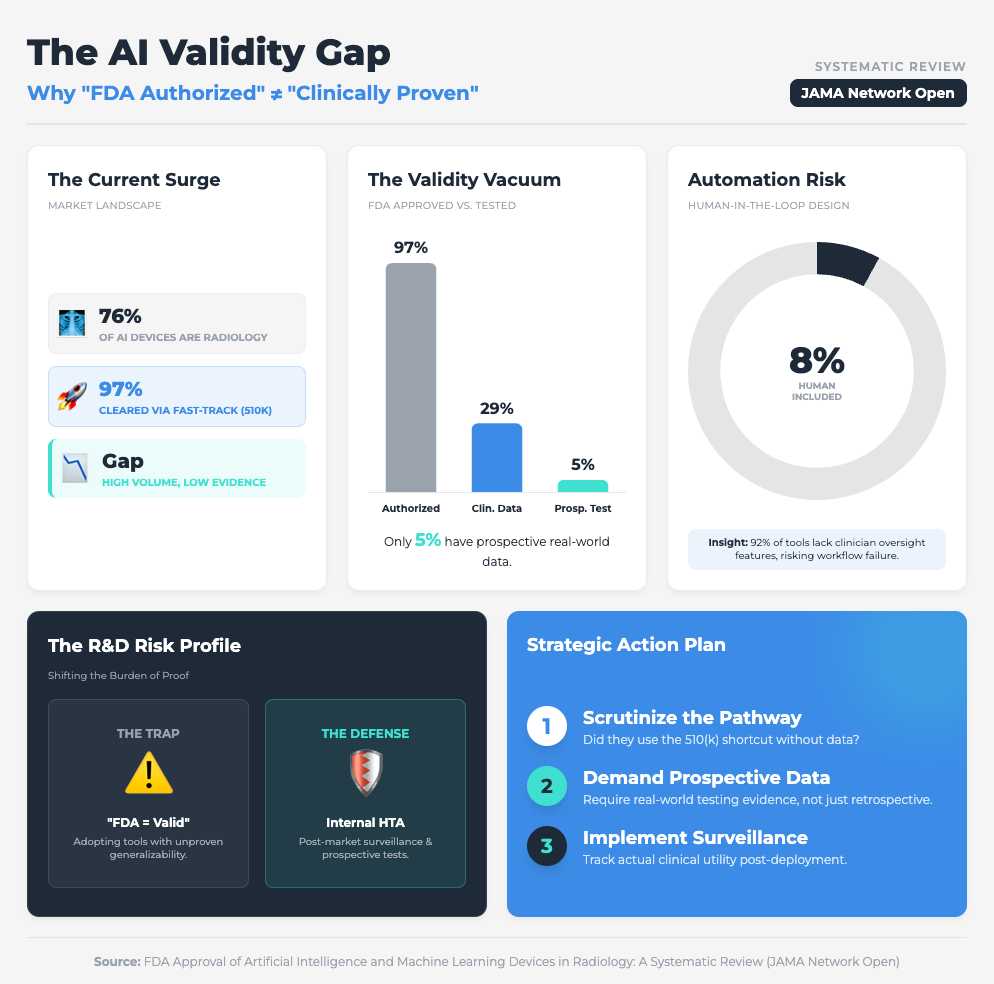
FDA Approval of AI/ML Devices in Radiology (4 min read)
Summary: A systematic review found that 76% of FDA-cleared AI devices utilized the 510(k) pathway, a route that often bypasses rigorous, independent clinical data requirements. With only 8% of these devices including a human-in-the-loop in testing, there is a significant gap between regulatory clearance and proven clinical generalizability.
Key Takeaway: Don’t conflate regulatory clearance with clinical utility. To ensure scalability, demand prospective testing from your vendors to prove the tool works in the real world, not just on a test dataset.
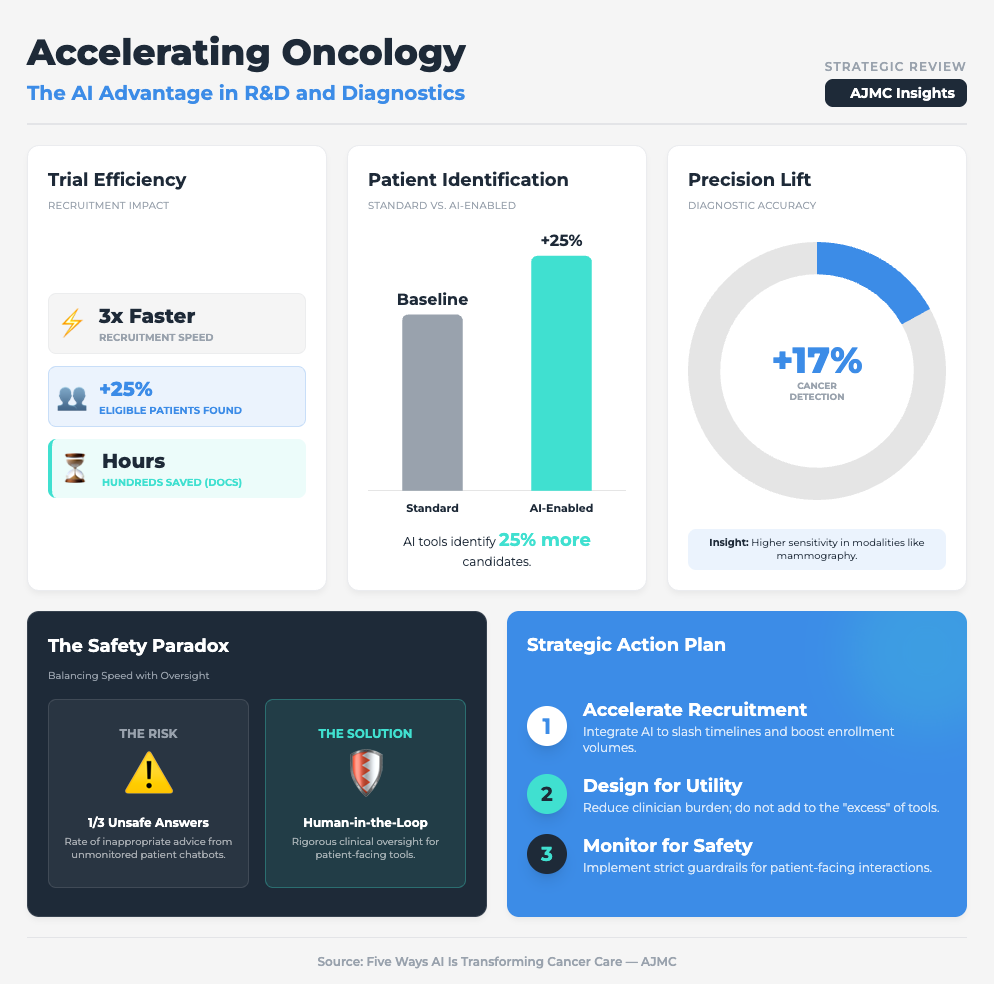
Five Ways AI Is Transforming Cancer Care (7 min read)
Summary: This briefing outlines how AI is drastically speeding up recruitment (up to 3x faster) but simultaneously overwhelming doctors with “tool fatigue” and “excess” dashboarding. The report emphasizes that while AI can identify up to 25% more eligible patients, it must be integrated into existing workflows to avoid increasing the administrative burden on oncologists.
Key Takeaway: Scalability dies when you add workload. Successful implementation requires integrated tools that demonstrably save hours on documentation, rather than just adding another dashboard to check.
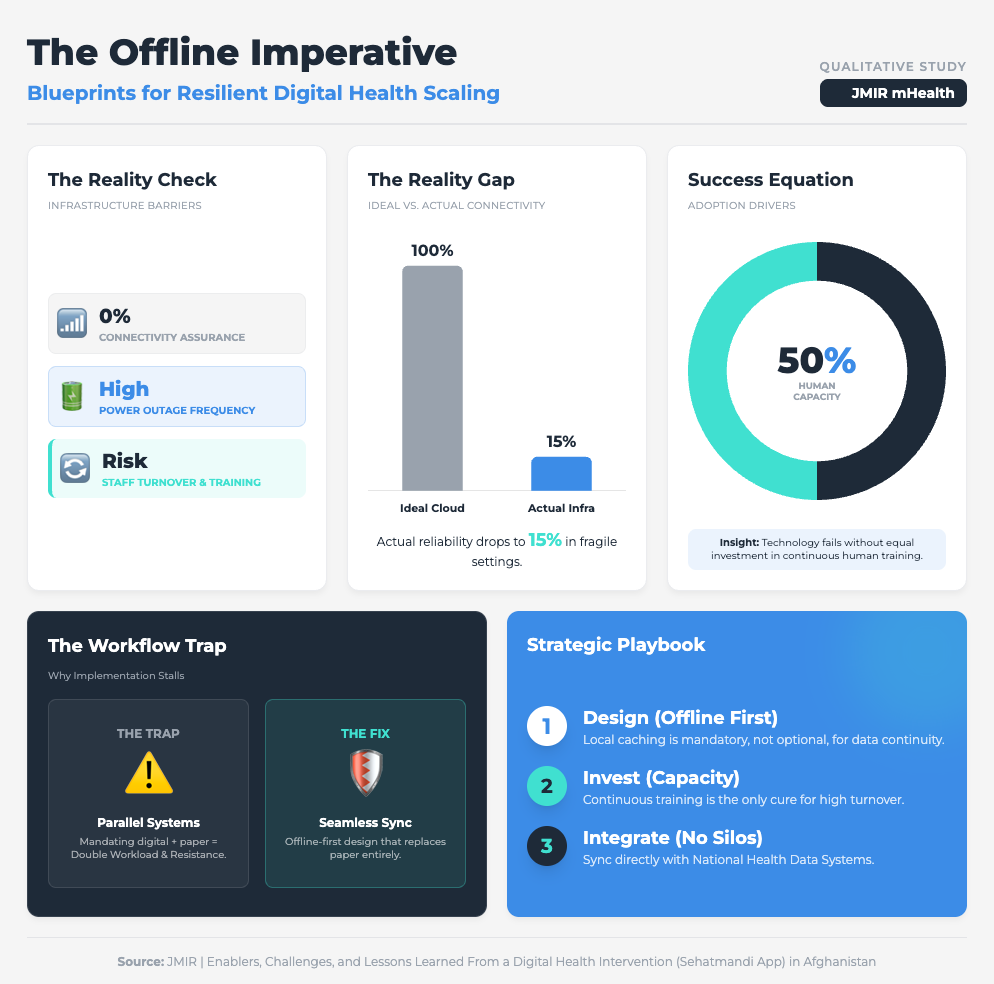
Enablers and Challenges from a Digital Health Intervention (10 min read)
Summary: An analysis of a health app in resource-constrained settings (Afghanistan) highlighted how infrastructure flaws can derail even the most well-intentioned digital interventions. High staff turnover and the requirement for dual data entry (paper and digital) were identified as major friction points that fueled resistance and threatened sustainability.
Key Takeaway: If your clinical trial sites have unstable internet, cloud-only AI will fail. Mandating “offline-first” capabilities and avoiding dual data entry are non-negotiable for global scalability.
The AI Revolution: Multimodal Intelligence in Oncology (15 min read)
Summary: Multimodal AI (MMAI) integrates heterogeneous datasets—including imaging, genomics, and clinical records—to significantly outperform single-mode models in predictive accuracy. This approach not only improves prognosis accuracy but also enables the use of “digital twins” for synthetic control arms, potentially reducing the need for large control groups in trials.
Key Takeaway: The future of R&D is MMAI and synthetic control arms. However, you cannot scale this without radical interoperability (standards like FHIR and OMOP) to break down data silos.

3 Steps To Build Scalable AI Solutions With Lasting Impact Even if You Have Skeptical Stakeholders
In order to achieve faster clinical trials and high-quality data, you’re going to need a handful of things: a focus on workflow, rigorous validation, and infrastructure resilience.
Let’s break down how to move from “cool pilot” to “standard of care.”
1. Engineer Trust into the Workflow
The first thing you need is to stop treating AI as a standalone answer and start treating it as a “second opinion” that needs validation.
Why? Because the JAMA study on dementia showed us that passive AI alone was ineffective. It was only when they combined the AI with a simple Patient-Reported Outcome (PRO) that diagnoses jumped by 31%. When the patient provided input first, the clinician trusted the subsequent AI flag more.
What you need to do:
Don’t just drop an algorithm into your clinical trial sites. Pair it with a human element—like a brief PRO or a validation step—that engages the user. This “human-in-the-loop” design isn’t a bug; it’s a feature that mitigates the “black box” fear and drives adoption.
2. Stress-Test for the “Real World” (Not Just the Lab)
Next, you need to ruthlessly audit the validation data of your AI partners and the infrastructure of your sites.
We know that 97% of FDA-authorized AI devices are cleared via the 510(k) pathway, which often skips prospective clinical testing. Furthermore, as seen in the Sehatmandi app study, if a tool requires internet to function, it will fail in resource-constrained sites.
What you need to do:
The Vendor Audit: Ask your AI vendors: “Show me the prospective clinical data,” not just their retrospective accuracy scores.
The Infrastructure Rule: Mandate offline capabilities for any digital data collection tool used in global trials. If the Wi-Fi cuts out and the app crashes, you lose data. If it queues data locally and uploads later, you win.
3. Demand Radical Interoperability
Finally, you need to break down the walls between your data types to leverage Multimodal AI (MMAI).
You cannot explore product differentiation or synthetic control arms if your imaging data sits in one server and your omics data sits in another. MMAI allows for “digital twins” and highly precise patient stratification, but it requires data to speak the same language.
What you need to do:
Stop building parallel systems. Require that new AI tools integrate with existing Health Management Information Systems (HMIS) or Electronic Health Records (EHR). Specifically, push for standards like FHIR and OMOP in your contracts. This ensures that as your company grows, your AI can ingest heterogeneous data to create the high-quality insights necessary for regulatory approvals.
PS...If you're enjoying Healthtech for Lifescience Leaders, please consider referring this edition to a friend.
And whenever you are ready, there are 2 ways I can help you:
AI Roadmap Kickstart Guide: Download my free guide on the 7 critical questions every pharma leader must answer before launching an AI initiative.
Strategy Session:Book a complimentary 30-minute AI Strategy Session with me to diagnose the biggest opportunities for AI within your current R&D pipeline.
November 21 - HealthTech Dose
November 21, 2025
This episode moves beyond conceptual discussions of Artificial Intelligence (AI) and focuses entirely on execution, delivering a clear, actionable roadmap for successfully implementing AI strategies. The mission is to shift the focus from small pilot projects toward full-scale operational integration across the entire drug development life cycle. To succeed this decade, executives must prioritize three immediate strategic mandates: Speed (rapid acceleration in clinical execution), Assurance (meeting regulatory requirements through rigorous validation and data quality), and Differentiation (using AI to drive superior product standing in the market).
The key strategic win lies in embracing AI not as pure automation, but as a powerful tool for augmenting human expertise across scientific inquiry and clinical decision-making.
Key Takeaways:
Accelerate clinical execution by embedding optimization engines into trial design workflows to simulate millions of potential scenarios and reduce planning delays.
Ensure regulatory assurance by prioritizing rigorous cross-cohort model validation against independent real-world data sets to prove generalizability and meet regulatory hurdles.
Achieve product differentiation through tailored patient experiences and microintervention frameworks that address specific behavioral concepts like “discounting the future”.
Unlock pipeline bottlenecks by investing in and rigorously validating patient-centric tools, such as Trial Specific Patient Decision Aids (TPDAs), to significantly boost comprehension in complex trials.
Prioritize strategies that genuinely augment human expertise (57% of AI use) by integrating AI into scientific inquiry and clinical decision-making, rather than just automating administrative tasks.
Show Notes:
[0:00 - 1:15] R&D leaders must shift from AI concepts to execution, focusing on three strategic mandates: speed, assurance, and product differentiation.
[1:15 - 2:20] AI drives acceleration by operational streamlining, embedding optimization engines like Phase V’s Trial Optimizer to simulate scenarios and reduce planning delays.
[2:20 - 3:30] Acceleration is maximized by virtual clinical trials, which use sophisticated modeling and real-world data (RWD)—such as the Mayo Clinic’s work in heart failure—to predict results and implement cost-saving synthetic arms.
[3:30 - 4:30] The second mandate, Assurance, requires rigorous model validation strategies, such as cross-cohort validation using independent data sets, illustrated by the development of the CARDIO model for HIV care.
[4:30 - 5:20] Ensuring trustworthy patient-facing AI requires interdisciplinary teams and techniques like RLHF (Reinforcement Learning from Human Feedback) to shape communication, minimize jargon, and actively prioritize patient comprehension.
[5:20 - 6:15] Differentiation is achieved via personalized, tailored experiences using microintervention software technology (DMIS) to address patient behavioral tendencies—such as “discounting the future”—and boost program effectiveness.
[6:15 - 7:15] Patient decision aids (TPDAs) are a vital product iteration for R&D, significantly boosting patient comprehension and unlocking clinical pipeline bottlenecks during complex trial recruitment.
[7:15 - End] The overarching strategic takeaway is that AI’s primary role is augmentation (57%), necessitating strategies that empower teams and integrate AI into scientific inquiry rather than focusing only on administrative automation.
Podcast generated with the help of NotebookLM
Source Articles:
Enablers, Challenges, and Lessons Learned From a Digital Health Intervention
The AI revolution: how multimodal intelligence will reshape the oncology ecosystem - Nature
FDA Approval of Artificial Intelligence and Machine Learning Devices in Radiology
AI-optimized trial shows mental health app can ease university student distress
Predicting the risk of preterm birth with machine learning and electronic health records in China
Digital Detection of Dementia in Primary Care: A Randomized Clinical Trial | JAMA Network Open
Five Ways AI Is Transforming Cancer Care—and Companies That Are Making It Happen
Development and testing of an electronic frailty index using Canadian ... - BMC Primary Care

It’s not inertia. It’s a trust problem.
November 18, 2025
HT4LL-20251118
Hey there,
When experienced R&D teams resist new AI tools, it’s not because they’re dinosaurs—it’s because they’re professionals.
As R&D leaders, we are under immense pressure to deliver faster clinical trials and streamline R&D. We see AI as the obvious path forward. But our experienced, long-standing teams often see it as a threat. We call it “inertia” or “resistance to change,” but that’s a lazy diagnosis. The truth is, their skepticism is often a rational, professional response to legitimate fears.
We’re deploying technology without addressing the three fundamental questions our experts are asking: 1) “Will this tool make my judgment irrelevant?” 2) “Can I trust this ‘black box’?” and 3) “Is this just more ‘innovation’ that means more work for me?” If we can’t answer these, we’ll never get the buy-in we need.
This week, we’re digging into the root causes of organizational resistance and how to solve them. We’ll cover:
Why “black box” models are your biggest adoption-killer.
How to stop “cognitive offloading” and empower expert judgment.
Reframing implementation from a tech problem to an organizational one.
If you’re an R&D leader trying to integrate AI without alienating your high-performing, long-standing teams, then here are the resources you need to dig into to build a strategy based on trust and transparency:
Weekly Resource List:
Ethical challenges in the algorithmic era (Approx. 30 min read)
Summary: This rapid review identifies five critical ethical risk dimensions for predictive analytics, including the erosion of professional autonomy and algorithmic bias. It finds that resistance is often rooted in fears of deskilling and a lack of clear accountability when an AI fails.
Key Takeaways: To counter this, you must prioritize human-machine collaboration, framing AI as an augmentative aid, not a replacement. Proactively audit for bias and, most importantly, establish a clear governance framework that defines responsibility when errors occur. This reduces the legal and ethical ambiguity that fuels skepticism.
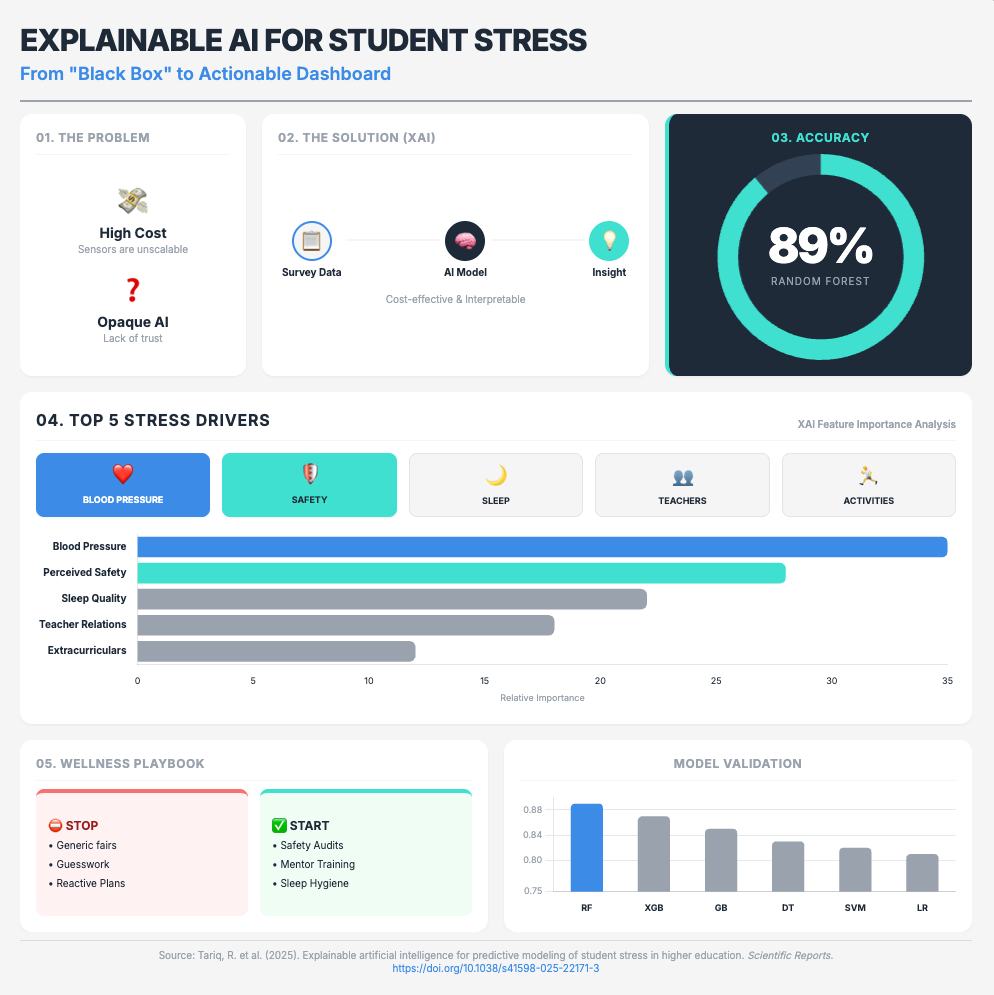
Explainable artificial intelligence for predictive modeling (Approx. 26 min read)
Summary: This study proves that “black box” models are a primary source of user skepticism. By using a simple Random Forest model with eXplainable AI (XAI), researchers could accurately predict student stress. The transparency from SHAP analysis (which identifies why a model made a prediction) was paramount for user adoption.
Key Takeaways: Mandate XAI (like SHAP) for all your predictive models. This transparency is the only way to build credibility with scientific teams. It shifts the conversation from a mysterious “black box” to a verifiable tool that provides actionable, data-driven insights.
Community-Based Organizations’ Approaches to Recruitment (Approx. 31 min read)
Summary: This study of a digital HIV prevention program found that implementation failed not because of the tech, but because of organizational barriers. High staff turnover, limited resources, and profound resistance to adapting traditional workflows were the real problems.
Key Takeaways: Stop using technical jargon. All communication about new tools must be in recipient-centered language focused on concrete benefits (e.g., “This cuts your data entry time”). You must proactively redesign workflows to integrate the tool, not just bolt it on. Success requires an executive mandate and sustained investment in training.

Generative Artificial Intelligence in Medical Education (Link) (Approx. 25 min read)
Summary: This viewpoint explores the core fear of senior experts: “cognitive offloading,” where users passively delegate critical thinking to GenAI, eroding their own skills. This is a primary driver of resistance from professionals who value their hard-won expertise.
Key Takeaways: You must train your teams for “critical engagement”—teaching them prompt engineering and bias identification so they interrogate AI, not just accept its output. A powerful strategy is to deploy Reasoning AI (which provides traceable logic) alongside GenAI (which provides creative hypotheses) to reinforce, not replace, structured critical thinking.

Opportunities and Challenges for Designing in Connected Health (Link) (Approx. 46 min read)
Summary: This expert workshop identified major barriers to adopting connected health systems. The two biggest were friction with existing workflows (”sociotechnical complexity”) and “alarm fatigue”—where frequent, non-critical alerts desensitize users.
Key Takeaways: Resistance is often a practical response to bad design. Use user-centered design to ensure new tools only produce high-priority, actionable alerts. And use participatory co-design to involve all stakeholders (not just managers) to map and align the digital solution with complex, real-world processes.

The 3 Real Reasons Your Experts Resist AI (And How to Fix Them)
To successfully integrate AI and achieve faster clinical trials, you need to stop treating resistance as a personality flaw. It’s a rational response from a highly skilled workforce. If you want high-quality data and adoption, you can’t just push—you have to solve the underlying trust issues.
Here are the three deep-seated, legitimate fears you must address head-on.
Fear #1: “This Tool Will Make My Expertise Obsolete”
Your best people—clinicians, senior scientists, data managers—spent decades building their critical judgment. Their greatest fear is “cognitive offloading” (Source 4), where a new tool encourages passive acceptance and erodes their professional autonomy (Source 1).
Why it’s a problem: When experts feel their judgment is being replaced by a machine they can’t see, they will disengage, work around the system, or leave.
How to fix it:
Mandate Critical Engagement: Your training can’t just be “how to use the tool.” It must be “how to interrogate the tool.” As highlighted in Source 4, this means mandatory training in prompt engineering and, more importantly, bias identification. Their job is to be the critical, empowered professional who validates or vetoes the AI’s output.
Combine AI Models: Don’t rely solely on Generative AI. As Source 4 suggests, pair it with Reasoning AI (like neurosymbolic models). This provides a traceable, logical justification for complex predictions, respecting your team’s need for verifiable, scientific logic.
Establish Reflective Oversight: Frame every tool as a “human-machine collaboration” (Source 1). Create governance committees and clear oversight pathways that prove to your team that an expert is always in the loop and holds the final decision-making power.
Fear #2: “I Can’t Trust a ‘Black Box’”
Skepticism is the cornerstone of the scientific method. When an AI model predicts a patient is at high risk or identifies a novel biomarker but can’t show its work, it violates the core principles of your R&D team. They resist because they cannot validate it.
Why it’s a problem: A lack of understanding of AI’s capabilities (a key persona challenge) is made worse by opacity. This fuels concerns about data privacy, reliability, and algorithmic bias, grinding adoption to a halt.
How to fix it:
Mandate eXplainable AI (XAI): As Source 2 demonstrates, transparency is paramount. Make XAI methodologies like SHAP (SHapley Additive exPlanations) a non-negotiable requirement for any predictive model you build or buy.
Show the “Why”: Use XAI to turn an opaque prediction into a verifiable insight. Instead of “This trial site will likely fail,” it becomes “This site is at risk because it scores low on startup speed and patient recruitment density” (Source 2). This gives your team an actionable, data-driven insight they can work with.
Proactive Bias Audits: Use this transparency to build ethical trust. As Source 1 recommends, implement mandatory bias monitoring using diverse, representative datasets. This proves you aren’t just deploying tech, but are actively ensuring it’s fair and equitable.
Fear #3: “This Is Just More Work for Me”
This is the most common and practical barrier. The resistance that looks like inertia is often just a rational response to “sociotechnical complexity” (Source 5) and “alarm fatigue.” If the new tool disrupts an existing, entrenched workflow, requires 10 clicks, or sends 100 pointless alerts, your team will rightfully ignore it to get their actual work done.
Why it’s a problem: Bad implementation creates friction. It positions innovation as a burden, not a benefit, reinforcing the idea that leadership is out of touch with on-the-ground realities.
How to fix it:
Stop Using Jargon: As Source 3 highlights, you must use benefit-focused, recipient-centered language. Don’t say, “We’re implementing a new RWD platform.” Say, “This new search tool will cut your protocol design research time from weeks to days.”
Redesign the Workflow First: Stop bolting tech onto broken processes. Use service process models (Source 5) and stakeholder co-design to map the existing workflow and redesign it with the new tool at its center. This mitigates the friction (Source 3) that dooms adoption.
Optimize Alerts: Combat “alarm fatigue” (Source 5). Use user-centered design to ensure alerts are only for significant, actionable events. If your “smart” system cries wolf every 10 minutes, it will be muted.
PS...If you're enjoying Healthtech for Lifescience Leaders, please consider referring this edition to a friend.
And whenever you are ready, there are 2 ways I can help you:
AI Roadmap Kickstart Guide: Download my free guide on the 7 critical questions every pharma leader must answer before launching an AI initiative.
Strategy Session:Book a complimentary 30-minute AI Strategy Session with me to diagnose the biggest opportunities for AI within your current R&D pipeline.
November 14 - HealthTech Dose
November 14, 2025
This episode moves beyond conceptual discussions of digital innovation and focuses entirely on execution. The mission is to shift the focus from why digital tools are important toward how to implement them when facing skepticism from teams. To succeed, executives must address three immediate strategic mandates: Speed (accelerating trial timelines), Assurance (ensuring data quality and trust), and Differentiation (creating real market value). The key strategic win lies in embracing a servant leadership mindset, reframing resistance not as a personnel problem, but as a product management hurdle.
Key Takeaways:
Treat Resistance as a Product Flaw: Resistance to new digital processes in R&D is a signal. It indicates that the new “product” (the trial design, the AI tool) may lack transparency or fail to address real-world complexity.
Adopt Servant Leadership: To overcome friction, leaders must shift from demanding compliance to enabling success. This means providing teams with the right tools, empathy-driven communication strategies, and the autonomy to iterate on processes.
Mandate Transparency to Build Trust: R&D teams are rationally skeptical of “black box” AI. To ensure data quality and adoption, leaders must mandate Explainable AI (XAI) from the start, turning AI from a mystery into an actionable tool that aids, rather than replaces, clinical judgment.
Prioritize Ethical Validation: Algorithmic bias is a critical product design flaw. Executives must build multi-site validation and bias mitigation into project budgets and stage-gates as a non-negotiable requirement to ensure tools are safe and effective for all intended populations.
Win Differentiation by Solving “Messy” Human Problems: True market differentiation doesn’t come from technology alone, but from solving the complex, human-centric problems that R&D often avoids (e.g., managing patients with multimorbidity).
Co-Design is Non-Negotiable: To create tools that get used, patient and clinician stakeholders must be involved in the design process from day one. Tools built in a vacuum may look good in theory but will ultimately fail to gain adoption.
Show Notes:
[0:00 - 0:45] Introduction: Today’s deep dive focuses on the profound organizational challenge in pharma R&D: implementing digital innovation (like digital biomarkers and AI) when facing skepticism from experienced teams.
[0:45 - 1:15] The Central Thesis: Resistance isn’t a personnel issue; it’s a product management hurdle. Overcoming this friction requires a “servant leadership” mindset to address strategies across three areas: accelerating trials, ensuring data quality, and creating market differentiation.
[1:15 - 2:10] Imperative 1: Accelerating R&D Timelines. The shift toward community-based studies (e.g., the Shanghai cardiometabolic health study) introduces new friction. The dream of a 5-year longitudinal dataset hinges entirely on patient adherence—like wearing a bracelet 16 hours a day, every day.
[2:10 - 3:45] A Servant Leadership Fix for Trial Friction: Lessons from an HIV prevention study show that recruitment success depended on communication. Successful teams dropped technical jargon for personalized, empathetic language. They iterated on the enrollment “product” by moving recruitment from public waiting areas to private clinic rooms, respecting the user.
[3:45 - 4:10] The Takeaway: Leaders must shift from demanding compliance to enabling success. If the user (patient or staff) can’t use the trial design as intended, the “product” (the trial) has a flaw.
[4:10 - 5:15] Imperative 2: Ensuring Data Quality & Trust. R&D teams are used to their metrics and are rationally skeptical of “black box” AI tools. A review of nursing predictive analytics showed that when nurses couldn’t understand how an AI derived a risk score, it actively undermined their own clinical judgment, and they reverted to old methods.
[5:15 - 6:30] Building Trust with Explainable AI (XAI): The answer isn’t “trust the algorithm”; it’s transparency by design. A student stress prediction model succeeded because it used XAI to show which inputs (blood pressure, sleep quality) drove the prediction. This turns a mysterious number into actionable evidence a clinician can use.
[6:30 - 7:35] The Ethical Mandate: Validation & Bias. Algorithmic bias is a critical product design flaw. Servant leadership means prioritizing ethical data governance by mandating multi-site validation, a step missing from many acquired brain injury tools, to ensure the product works for everyone it’s intended to serve.
[7:35 - 8:40] Imperative 3: Creating Market Differentiation. Real differentiation comes from solving the “messy human problems” R&D traditionally avoids. The cardiometabolic study aims to build a digital twin for older patients with multimorbidity—the exact population almost always excluded from standard clinical trials.
[8:40 - 9:40] Co-Design as a Differentiator: Big decisions (like joining a trial or using a tool) are full of “human vagueness” (social factors, passion, family). Tools must be co-designed with patients and clinicians from day one to account for this subjective reality, or they will fail in the real world.
[9:40 - 10:54] Final Takeaways: Resistance is a signal that your new process lacks transparency or fails to address real-world complexity. R&D executives must embrace servant leadership, mandate transparency (XAI), and anchor product differentiation in solving messy, human-centric problems through co-design.
Podcast generated with the help of NotebookLM
Source Articles:
Patient and public involvement in the co-design of digital health interventions for behavior change: a scoping review of reviews
An explainable AI-based decision support system for career choice guidance
Team-Based Precision Oncology: Advancing Value and Access in Cancer Care
Ethics of Artificial Intelligence in Nursing: A Scoping Review
Immunology’s Next Chapter: The Promise of AI and Multi-Omics
Interdisciplinary Development and Fine-Tuning of CARDIO, a Large Language Model for Cardiovascular Health Education in HIV Care: Tutorial
AI in Trials: De-Risked
November 11, 2025
HT4LL-20251111
Hey there,
Adopting AI in clinical trials feels less like an innovation strategy and more like a compliance nightmare waiting to happen.
As R&D leaders, we’re caught between the pressure to accelerate trials and the very real risks of immature tech. You’re worried about data privacy, regulatory blowback, and the “black box” problem. What happens when an algorithm “hallucinates” on patient data? How do you prove to the FDA or EMA that your AI-driven endpoint is valid? Just “hoping for the best” isn’t a strategy; it’s a liability.
The good news is we’re moving past ad-hoc adoption and into an era of structured, evidence-based integration.
Today, we’re looking at how to de-risk AI in practice:
Why a “risk-stratified” approach is your most important first step.
How to prove AI value to regulators (hint: use their language).
The one thing that makes or breaks clinician trust in AI tools.
If you’re cautious about AI but know you can’t afford to be left behind, then here are the resources you need to dig into to build a compliant, high-trust program:
Weekly Resource List:
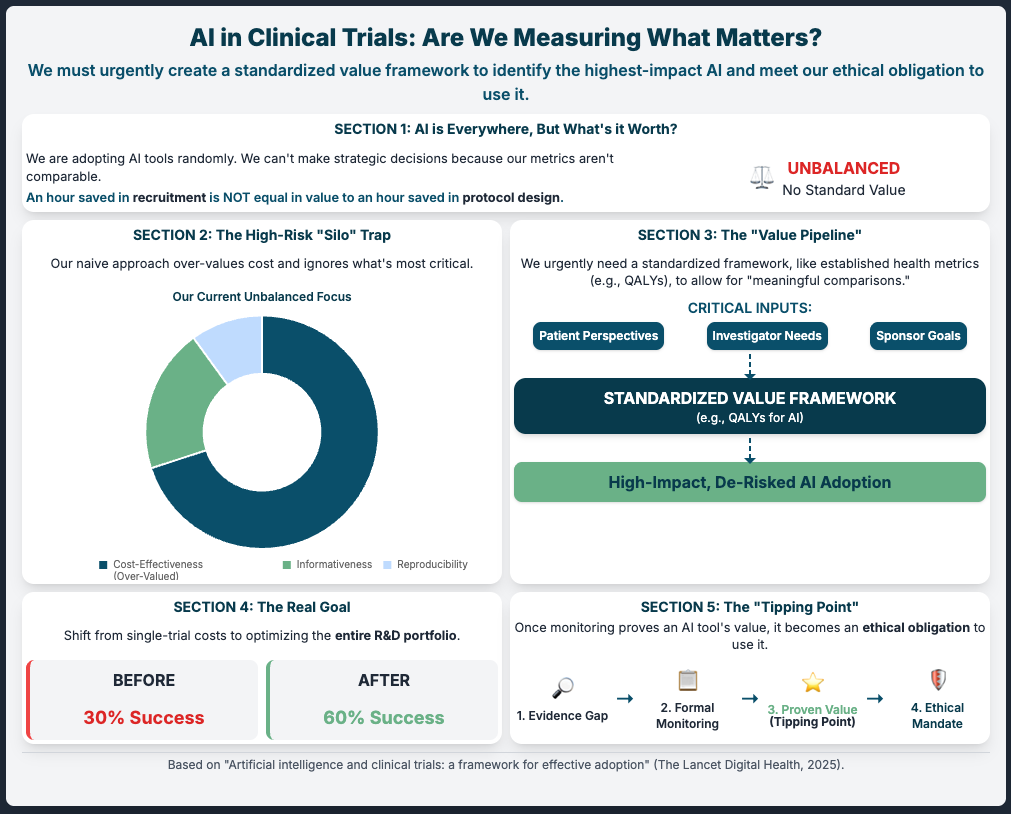
Artificial intelligence and clinical trials: a framework for effective adoption (Reading Time: ~5 min)
Summary: This article argues that our biggest risk is ad-hoc adoption. Instead of just plugging in tools, we must first build a standardized value framework. This means getting community and patient input to define what “good” looks like before we deploy. It suggests we have an ethical obligation to use proven AI, and the only way to prove it is to measure it against a shared standard.
Key Takeaways:
Establish a Value Framework: Don’t just ask “does it work?” Ask “how do we measure its impact?” Define this before you invest.
Mandate Evidence Generation: Force all new AI tools to be measured against this framework to justify their use.
Monitor (Observe): Create an “observatory” (even just an internal one) to track what works and what doesn’t. This builds the evidence base to justify use to regulators.
Artificial intelligence in clinical trials: A comprehensive review... (Reading Time: ~25-30 min)
Summary: A massive review showing AI can accelerate timelines (30-50%) and cut costs. But it nails the primary blockers: bias, interoperability, and regulatory uncertainty. The core solution proposed is a risk-stratified framework—a practical starting point for any R&D organization.
Key Takeaways:
Implement Risk-Stratification: This is your #1 action. Separate low-risk (e.g., automating repetitive tasks in data management) from high-risk (e.g., patient eligibility).
Mandate Safeguards: For high-risk apps, require physician review. This de-risks the “black box” immediately.
Prioritize XAI: Invest in Explainable AI. If you can’t explain how the AI decided, regulators and clinicians won’t trust it.
Use Federated Learning: Solve the data privacy/GDPR risk by training models on-site without moving or pooling sensitive patient data.
Task-Technology Fit of Artificial Intelligence-based clinical decision support systems... (Reading Time: ~25-30 min)
Summary: This qualitative review explains why clinicians (your PIs) reject AI tools, even “smart” ones. It’s because the AI lacks context (like bedside notes). The key to de-risking adoption is to position AI as a complement, not a replacement.
Key Takeaways:
Design for Action: Don’t give clinicians a “7.5% risk score.” Give them a 3-tier “Low/Medium/High” visual. It’s more actionable and trusted.
Position as a “Reflective Tool”: Frame the AI as an “alert system” to prevent oversight or a “second opinion” to prompt re-evaluation. This removes the risk of it overriding clinical judgment.
Beware “Deskilling”: A key long-term risk. Ensure AI supports, not erodes, your team’s expertise.
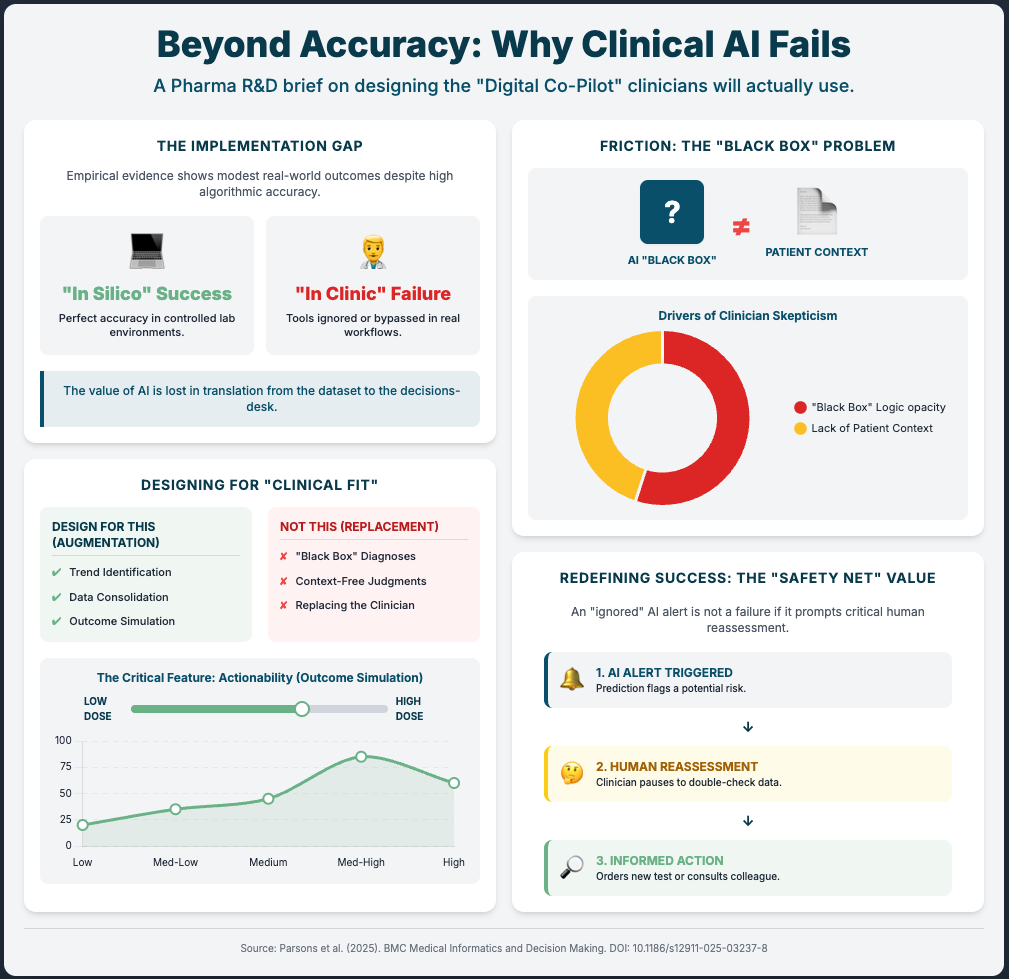
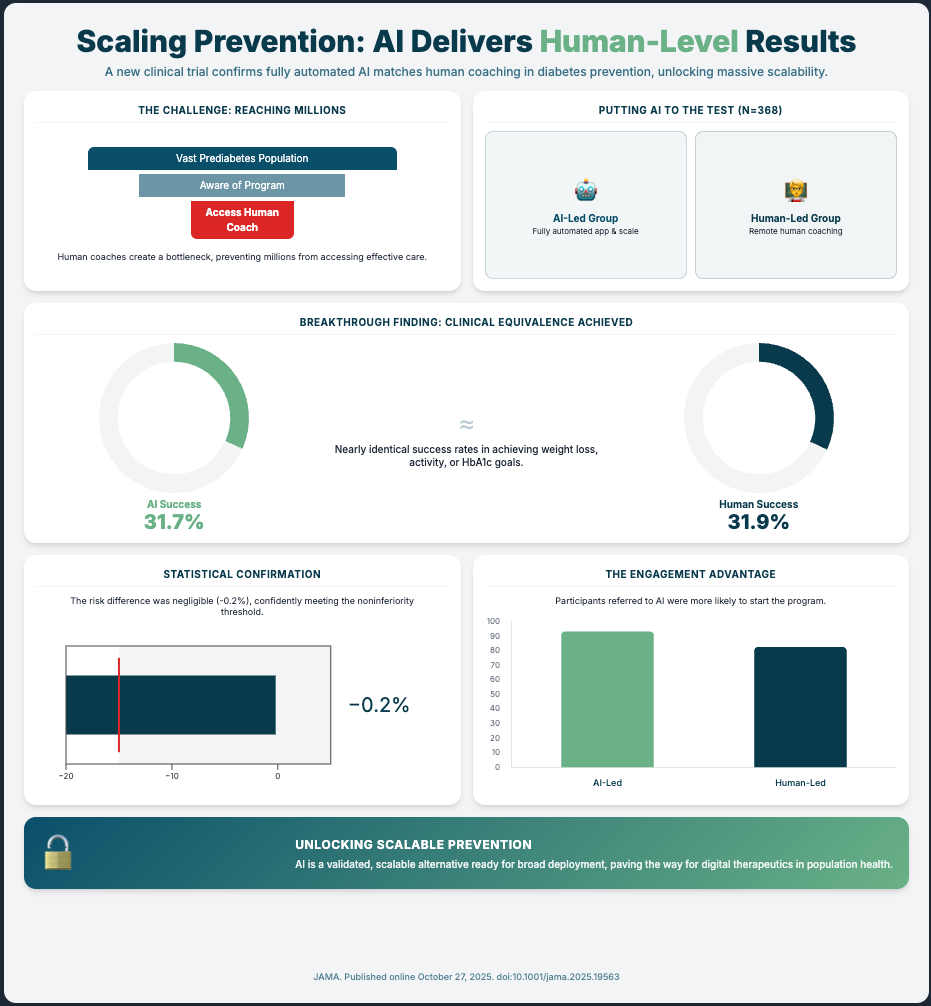
An AI-Powered Lifestyle Intervention vs Human Coaching... (Reading Time: ~6 min)
Summary: This is your compliance playbook in action. An AI-led digital therapeutic for diabetes prevention was tested against the “gold standard” (human coaches) in a noninferiority RCT. The AI met the standard.
Key Takeaways:
Use Noninferiority Trials: This is the language regulators understand. To de-risk a new AI/DTx tool, prove it’s “at least as good as” the current standard of care. This is your validation pathway.
Automate for Scale: This trial proves you can scale an evidence-based program with full automation, de-risking the human variability and cost factors.
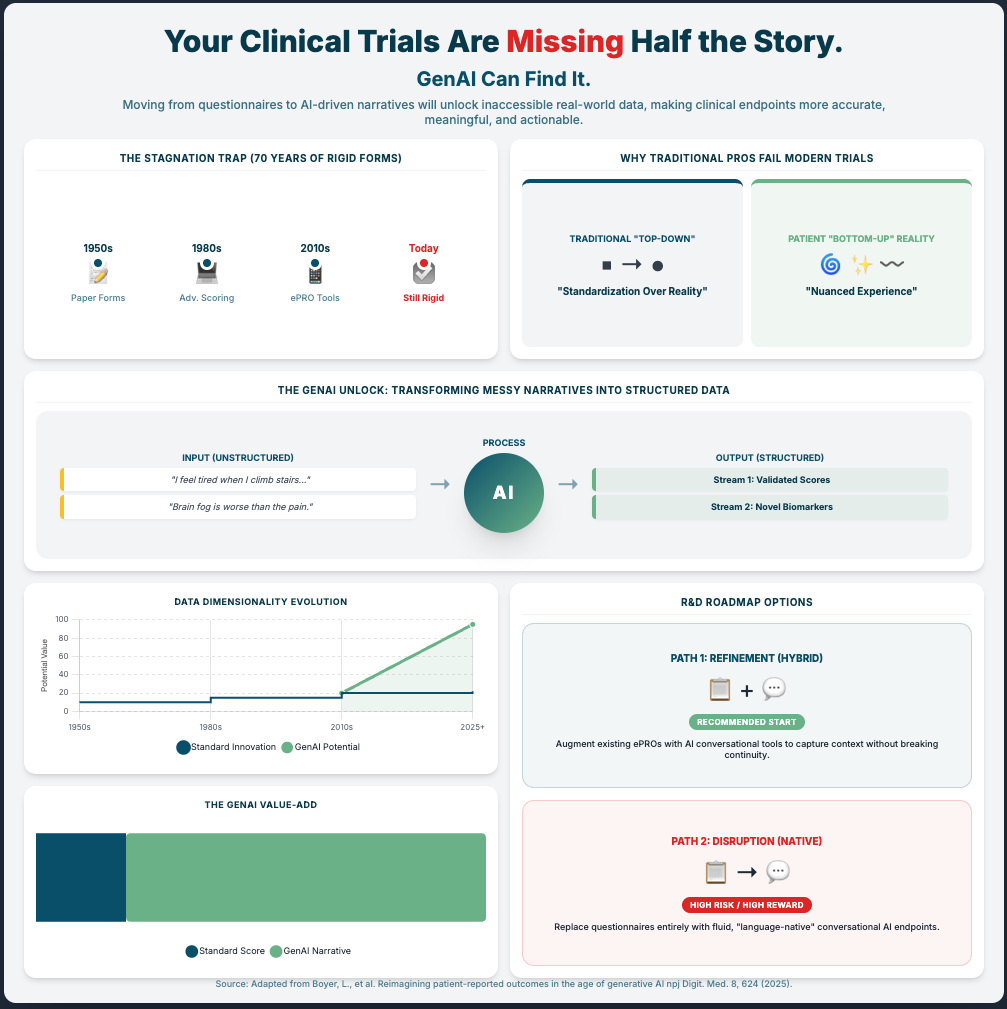
Reimagining patient-reported outcomes in the age of generative AI. (Reading Time: ~20-25 min)
Summary: Generative AI could revolutionize PROs by moving from static surveys to rich, narrative conversations. But it brings huge risks: hallucinations and bias. The only way to de-risk this is to build new validation methods and hybrid models.
Key Takeaways:
Mitigate Hallucinations: Don’t use only GenAI for high-stakes clinical work. Invest in hybrid AI architectures that combine a flexible LLM (for conversation) with a rigid, traditional ML model (for interpretable scoring).
Develop New Validation Standards: You must create new validation methods for these tools. You can’t use 1980s psychometrics on 2025 AI.
Conduct Bias Audits: Proactively audit your GAI models for socioeconomic and cultural bias before deployment. This is a non-negotiable regulatory and ethical step.
3 Steps To De-Risk Your AI Strategy (Even if You’re Starting from Scratch)
In order to build an AI program that regulators and your clinical teams will trust, you’re going to need a handful of things.
It’s not about buying the flashiest tool; it’s about building a robust, evidence-based framework. Let’s break down the practical steps.
1. Start with a Risk-Stratified Framework
The first thing you need is a simple way to categorize risk. Stop thinking of “AI” as one big, scary thing. A risk-stratified framework is your most practical first step.
Your organization should classify all potential AI applications into tiers (e.g., Low, Medium, High).
Low-Risk: Automating repetitive tasks, like QC-ing data fields in a report or internal site feasibility assessments. These are perfect “quick wins” to build confidence with minimal compliance overhead.
High-Risk: Anything that directly touches patient eligibility, diagnosis, or treatment dosing.
For your high-risk applications, you mandate a “human-in-the-loop” safeguard. As one of this week’s papers suggests, this could be a required physician review or PI approval. This single step immediately de-risks the “black box” problem from a regulatory and safety perspective. You’re not replacing human judgment; you’re augmenting it.
2. Prove It: Use the “Noninferiority” Playbook
To get regulators on board, you have to speak their language. The clearest path to validating a new AI tool is to prove it’s “at least as good as” the current gold standard.
Look at the AI-led Diabetes Prevention Program study. They didn’t try to prove the AI was better than human coaches (a high bar). They ran a noninferiority RCT and proved it was statistically noninferior. This gives them a rock-solid case for regulatory approval and reimbursement. It’s a clean, established, and de-risked validation pathway.
Identify an area where you have a costly, human-led process (e.g., patient follow-up, adherence coaching). Design a pilot to test an automated AI solution against it using a noninferiority-style benchmark. This builds concrete evidence of value and safety, which is exactly what your compliance team and the FDA want to see.
3. Solve the “Trust” Problem with Task-Technology Fit
Even if your AI is FDA-approved, it’s useless if your clinical teams won’t use it. Clinicians reject AI when it overreaches or lacks real-world context.
The risk of “clinician deskilling” or “automation bias” is real. The safest, most compliant way to deploy AI is to ensure it has perfect “Task-Technology Fit.” Instead of an AI that replaces judgment, deploy one that complements it.
Frame your AI tools as “alert systems” or “reflective prompts.” For example, an AI-CDSS shouldn’t say “Treat with X.” It should say, “Patient matches criteria for high-risk. Have you considered [protocol]?” This keeps the clinician as the decision-maker, maintains their skills, and massively reduces your liability. And when dealing with new tech like GenAI, apply this same logic: use hybrid models that combine GenAI’s flexibility with traditional ML’s interpretability. This mitigates the risk of hallucinations and gives you a “de-risked” path to innovation.
PS...If you're enjoying Healthtech for Lifescience Leaders, please consider referring this edition to a friend.
And whenever you are ready, there are 2 ways I can help you:
AI Roadmap Kickstart Guide: Download my free guide on the 7 critical questions every pharma leader must answer before launching an AI initiative.
Strategy Session:Book a complimentary 30-minute AI Strategy Session with me to diagnose the biggest opportunities for AI within your current R&D pipeline.
November 7 - HealthTech Dose
November 7, 2025
This episode moves beyond conceptual discussions of Artificial Intelligence (AI) and focuses entirely on execution, delivering a clear, actionable roadmap for R&D leaders. The mission is to shift the focus from small pilot projects toward full-scale operational integration by proving AI can meet tough GxP regulatory standards. To succeed, executives must prioritize three immediate strategic mandates:
Speed (accelerating operations and approvals),
Assurance (meeting regulatory requirements through rigorous validation), and
Differentiation (using AI to drive superior access and efficiency).
The key strategic win lies in embracing AI not as pure automation, but as a powerful tool for augmenting human expertise, turning static data archives like the Trial Master File (TMF) into an intelligent, predictive co-pilot for clinical operations.
Key Takeaways
Establish Clinical Equivalence First: Before scaling, AI must prove it performs as well as or better than the human standard. A randomized trial for a Diabetes Prevention Program (DPP) showed an AI-led model was statistically non-inferior to the human-coach model, validating the technology.
Leverage AI for Scalability and Access: AI’s true power isn’t just matching human performance but overcoming logistical bottlenecks. While only 3% of eligible adults enroll in traditional DPPs, the AI-led trial drove significantly higher initiation (93.4% vs 82.7%) and completion (63.9% vs 50.3%).
De-Risk Diagnostic AI with Rigorous Validation: For granular clinical assessments, validation must be absolute. A virtual concussion study showed that while some remote measures are reliable (VOMS reliability: 0.93), others (Saccades reliability: 0.35) are “barely better than chance” and represent a huge liability risk if used improperly.
Implement a “Human in the Loop” (HITL) GxP Framework: The non-negotiable answer for de-risking probabilistic AI is the HITL model. This framework stands on three pillars: 1) Stringent Model Validation (e.g., >95% accuracy for critical documents), 2) Defined Confidence Thresholds (e.g., <85% triggers human review), and 3) Rock-Solid Audit Trails.
Identify Interoperability as the “Silent Killer” of Scaling: The primary barrier to enterprise AI is often legacy systems. The Novartis/IBM Watson collaboration, for example, found integration costs were $250,000 to $500,000 per instance and required 6-8 months of custom work per site, making scaling economically unfeasible.
Show Notes
[0:00 - 1:00] Introduction: R&D leaders must move AI from impressive pilots to enterprise-wide GxP-compliant systems. The goal is to de-risk AI integration and turn the Trial Master File (TMF) from a static archive into an intelligent co-pilot.
[1:00 - 2:00] The first hurdle for R&D executives: Proving clinical equivalence. Does the AI perform as well as, or better than, the current human-led standard?.
[2:00 - 3:00] Evidence for equivalence: A randomized trial comparing an AI-led Diabetes Prevention Program (DPP) to a human coach model. The AI was statistically non-inferior, with a tiny -0.2% risk difference, well within the 15% margin.
[3:00 - 4:00] Beyond equivalence: AI’s advantage in scalability and reach. Traditional DPPs have a massive participation problem (~3% enrollment). The AI trial showed much higher initiation (93.4%) and completion (63.9%) rates.
[4:00 - 5:00] This data challenges existing CDC standards that require a human coach, a major bottleneck. Pivoting to granular assessments: The challenge of virtual concussion tests, which demand absolute accuracy.
[5:00 - 6:00] A mixed bag of validation: In the concussion study, VOMS (vestibular ocular motor screening) showed excellent reliability (0.93). However, simple coordination tests and Saccades (eye movement) showed poor reliability (0.35), making them a huge liability risk.
[6:00 - 7:00] Embedding AI into GxP compliance: The TMF. Traditional TMF QC relies on sampling (5-10%) and is reactive, finding errors weeks or months late. AI can check 100% of documents instantly.
[7:00 - 8:00] The real game-changer is “predictive quality”. AI can spot correlations between TMF timeliness and site performance, creating an early warning system and moving QC from reaction to prevention.
[8:00 - 9:00] The framework for de-risking: The non-negotiable “Human in the Loop” (HITL) model. Pillar 1: Stringent validation (e.g., >95% accuracy for consent forms). Pillar 2: Defined confidence thresholds (e.g., <85% certainty flags for human review).
[9:00 - 10:00] Pillar 3: Rock-solid audit trails (logging AI recommendation, confidence, and human action). Ongoing governance is essential to manage model drift (degrading performance) and automation bias (humans rubber-stamping AI).
[10:00 - 11:00] The biggest practical barrier to scaling: Data interoperability. The Novartis/IBM Watson collaboration was effective (78% accuracy), but integration costs were $250k-$500k per instance.
[11:00 - 12:00] Interoperability as the “silent killer”. Integrating with one hospital’s Epic system took 6-8 months of custom work. Multiplying this by hundreds of trial sites makes enterprise scaling “practically impossible”.
[12:00 - End] Justifying the cost (ROI): Quantify efficiency gains that shorten timelines. AI data cleaning can cut biostatistician time by 60-80% (e.g., 80 hours down to 16), leading to faster database locks and submissions.
Podcast generated with the help of NotebookLM
Sources:
Artificial intelligence and clinical trials: a framework for effective adoption
Best Practices for Data Modernization Across the United States Public Health System: Scoping Review
Artificial Intelligence-Powered Internet of Medical Things in Radiation Oncology
Study Snapshot and Updated Ethics Documentation Available for APA-SM Study
Reimagining patient-reported outcomes in the age of generative AI

Is your new AI partner a liability?
October 28, 2025
HT4LL-20251028
Hey there,
The single biggest threat to your AI strategy isn’t the technology—it’s the vendor you choose to partner with.
The market is flooded with AI solutions, all promising to accelerate drug discovery and streamline clinical trials. But behind the hype, a staggering number of these projects are failing, not because of a faulty algorithm, but due to poor integration, overlooked security risks, and a fundamental mismatch between the tech and the actual R&D problem. This leaves leaders like us hesitant, concerned about wasting millions on immature technology that can’t handle our proprietary data or meet strict regulatory standards for data quality and privacy.
So today, we’re cutting through the noise. We’ll look at:
Why most AI partnerships are doomed from the start.
The hidden compatibility and security risks in a vendor’s tech stack.
A framework for choosing partners who deliver real, measurable value.
Let’s dive in.
If you’re tasked with driving innovation but need a pragmatic way to vet and manage the overwhelming number of AI vendors, then here are the resources you need to dig into to build a resilient and effective AI strategy:
Weekly Resource List:
Algorithmic fairness in medicine and health (16-minute read)
Summary: This article is a critical look at how AI in healthcare can worsen health disparities if not carefully managed. It explains that algorithms trained on biased data often favor privileged groups, creating inequitable outcomes.1 The authors argue for rigorous evaluation, transparency, and integrating fairness metrics into the entire AI lifecycle.
Key Takeaways: As an R&D leader, you are accountable for the ethical implications of the tools you deploy. Prioritize vendors who are transparent about their data sources and bias mitigation strategies. Mandating “fairness by design” isn’t just ethical—it’s a crucial risk management strategy to ensure data quality and avoid regulatory blowback.
Formative Evaluation of an AI-powered Virtual Assistant (22-minute read)
Summary: This study provides a transparent look at the real-world challenges of deploying a first-generation AI tool for managing health data. Despite high patient interest, the prototype was rated “marginally acceptable” due to immature components, poor integration between tools, and a lack of explainability.
Key Takeaways: This is a powerful reminder to look under the hood. A vendor’s slick demo might hide a fragile backend of poorly integrated, immature tools. Your due diligence must assess the entire tech stack, not just the algorithm itself. Prioritize vendors with proven, stable solutions and a clear roadmap for improving usability and integration.

2025: The State of AI in Healthcare (18-minute read)
Summary: This market analysis shows that while AI adoption is surging in healthcare, Pharma R&D is still in an experimental phase. Agile startups are capturing the majority of new AI spending, while established incumbents are integrating AI into their platforms. The key trend is that leading organizations are prioritizing mature, low-risk solutions with a fast ROI.
Key Takeaways: The vendor landscape is fragmented and complex. You need a strategy that can evaluate both nimble startups and established players. Focus on a vendor’s ability to securely integrate with your proprietary R&D data. Start with smaller, pilot projects to validate a vendor’s performance and reliability before scaling to business-critical applications.

Why Do Most Artificial Intelligence Projects Fail? (5-minute read)
Summary: Based on interviews with data scientists, this RAND report finds that over 80% of AI projects fail—double the rate of traditional IT projects.2 The top reasons are not technical, but strategic: miscommunicating the project’s purpose, insufficient data, weak infrastructure, and applying AI to the wrong problems.
Key Takeaways: The most common mistake is buying technology in search of a problem. Before you even talk to a vendor, you must rigorously define the specific R&D challenge you need to solve. Your vendor selection criteria should be laser-focused on that problem, ensuring compatibility and security are addressed from day one.

Virtual Communities in Cancer Care (38-minute read)
Summary: This extensive review examines the challenges of implementing digital health communities. While valuable for patients, these tools often fail due to low user retention, lack of integration with existing health systems, and unaddressed data privacy concerns. Success requires organizational readiness and user-centric design.
Key Takeaways: This paper isn’t about AI, but its lessons are directly applicable to vendor management. Any digital tool, no matter how innovative, will fail if it doesn’t integrate into workflows, protect user data, and meet the real needs of its users. Mandate that vendors provide clear evidence of user-centric design and robust security protocols.

3 Rules to Drive Real R&D Impact with AI, Even if You’re Drowning in Vendor Hype
To successfully navigate the vendor chaos and turn AI’s potential into tangible results, you need a disciplined framework that protects your organization from risk and wasted investment.
Here are the three rules I use to evaluate any potential AI partner.
Rule #1: Start with the Problem, Not the Platform
The RAND report is clear: the #1 reason AI projects fail is a poorly defined purpose. It’s easy to get mesmerized by a vendor’s platform that promises to do everything. Don’t fall for it.
Before you even schedule a demo, define a single, high-value problem within your R&D pipeline. Is it identifying patient subgroups for a trial? Optimizing a specific step in discovery? Once that problem is crystal clear, evaluate vendors only on their proven ability to solve it. This forces you to prioritize real-world utility over a long list of features you’ll never use, ensuring a faster path to ROI.
Rule #2: Interrogate the Entire Tech Stack
As the Frontiers study showed, a vendor’s solution is often a patchwork of different tools, some mature and some barely functional. A beautiful user interface can easily hide a nightmare of integration and data transfer issues on the backend.
You must demand full transparency into their entire technology stack. Ask tough questions: How do the components integrate? What are the data transfer protocols? Can you demonstrate the reliability and scalability of each part, not just the final output? A trustworthy partner will welcome this scrutiny. This approach ensures compatibility with your existing systems and prevents you from inheriting a mountain of technical debt.
Rule #3: Make Security and Ethics Non-Negotiable
In our industry, data is everything. A vendor that is casual about security, privacy, or algorithmic bias is not a partner; it’s a massive liability. The insights from the BMC and JMIR articles underscore this point.
From the very first conversation, make your security and ethical requirements non-negotiable. This includes compliance with GDPR and HIPAA, transparent data governance, and auditable methods for mitigating bias. A vendor’s hesitation to provide clear documentation on these fronts is an immediate red flag. Building this foundation of trust protects your patients, your IP, and your company’s reputation.
PS...If you're enjoying Healthtech for Lifescience Leaders, please consider referring this edition to a friend.
And whenever you are ready, there are 2 ways I can help you:
AI Roadmap Kickstart Guide: Download my free guide on the 7 critical questions every pharma leader must answer before launching an AI initiative.
Strategy Session:Book a complimentary 30-minute AI Strategy Session with me to diagnose the biggest opportunities for AI within your current R&D pipeline.